Enterprise Data Optimization: The MySQL to AWS S3 Migration
Architecting a high-performance storage strategy to eliminate database bloat, reduce infrastructure costs by 30%, and ensure scalable file management.
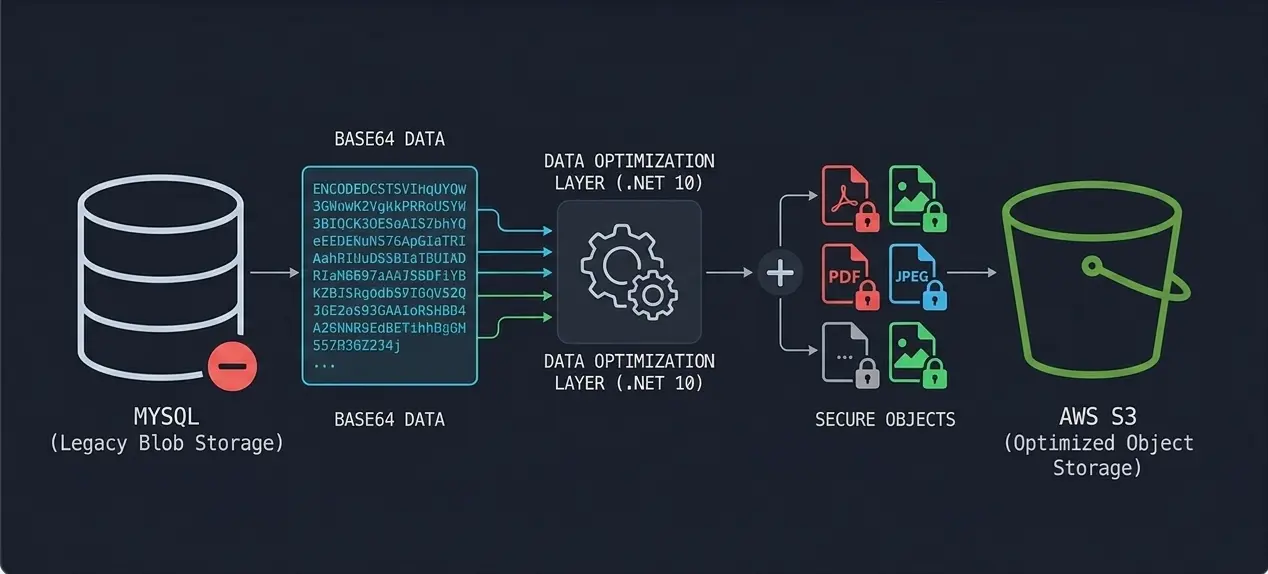
Overview
The core logistics platform was originally designed using a monolithic data approach, where all files including large shipping labels, customer documentation, and photos were encoded as Base64 strings and stored directly within MySQL columns. As the platform scaled, this led to exponential database growth, causing significant performance degradation during query execution and making database backups increasingly slow and risky.
To resolve this, I engineered a storage decoupling strategy to move all binary data to AWS S3. This involved creating a high-performance migration pipeline and a new service layer in .NET to handle secure object streaming via pre-signed URLs. The result was a leaner database, faster application response times, and a major reduction in cloud storage expenditure.
Legacy Upload Process (The Memory Bottleneck)
Legacy Retrieval Process (The Bandwidth Hog)
Goals & Challenges
Goals
- Reduce database storage footprint by offloading binary storage from MySQL to object storage (S3)
- Improve system scalability by decoupling file management from the relational database engine.
- Implement a secure access layer using AWS S3 Pre-signed URLs to protect sensitive logistics documentation.
- Eliminate the 33% storage overhead caused by Base64 encoding at the database level.
- Reduce server memory and CPU usage during file upload/download flows by eliminating full in-memory transformations.
Key Challenges
- Executing a safe, data-complete migration within a strictly scheduled maintenance window to prioritize data integrity.
- Ensuring the transition from DB-blobs to S3-references was completely transparent to the end-users.
- Maintaining strict access control for private customer files once they left the internal network environment.
- Handling partial failures and ensuring consistency between database records and S3 objects (avoiding orphaned files or broken references)..
Major Problems
- Base64 Storage Overhead (~33%), inflated storage size, larger indexes, slower I/O.
- Critical Memory Bottleneck, Files are fully loaded into memory during both upload and retrieval, causing:High RAM usage, Increased GC pressure and Risk of OOM under concurrency.
- Constant Base64 encode/decode cycles add unnecessary CPU load on every request.
- Database Misuse (Core Design Flaw), MySQL is being used as a blob store instead of what it’s good at (relational data), leading to: Slower queries, Larger backups, Poor scaling characteristics.
- Bandwidth Amplification, base64 increases payload size over the wire, meaning: Slower responses, Higher network costs, Worse performance for mobile clients.
Solutions & My Contributions
Modern Upload Process (Presigned URL + Event-Driven)
Modern Private Retrieval (Pre-signed URLs)
Data Migration Process (Maintenance Window)
Technical Architecture
- Developed a purpose-built .NET migration script that processed legacy Base64 data in controlled batches, decoding and streaming files directly to S3 in a diskless manner. The pipeline was designed to be idempotent and resumable, allowing safe retries without duplicating objects or corrupting database references in the event of partial failures. Batch sizing and throughput were tuned to meet strict maintenance window constraints while maintaining data integrity.
- Refactored the data access layer to replace database-stored blobs with lightweight S3 object references. Introduced a resolution layer responsible for generating pre-signed URLs on demand, fully decoupling file retrieval from the relational database and eliminating binary payload handling within the application layer.
- Configured S3 Lifecycle Policies to automate data tiering, further optimizing costs for older, less-frequently accessed documents.
- Designed an event-driven validation pipeline using AWS SQS and a .NET Background Service to decouple upload confirmation from persistence logic. Instead of trusting client-side acknowledgements, the system reacts to native s3:ObjectCreated events, validates uploaded objects via ETag inspection, and asynchronously updates the database state. The SQS consumer was implemented as an idempotent handler to safely process duplicate messages under SQS’s at-least-once delivery model, ensuring consistency in an eventually consistent architecture.
- Implemented compensating mechanisms to handle edge cases where uploads succeeded but downstream processing failed, preventing orphaned S3 objects and stale database records. This ensured long-term consistency between storage and metadata layers despite asynchronous processing boundaries.
- Introduced structured logging and monitoring across the upload and processing pipeline to track system health, SQS message handling, and failure scenarios, enabling faster debugging and operational visibility in a distributed environment.
Performance Optimizations
- Completely offloaded file payload processing from the .NET monolith by introducing pre-signed POST policies. Clients upload files directly to S3 using multipart/form-data, removing the backend from the data path entirely. This eliminated CPU-intensive encoding/decoding operations and reduced memory usage by avoiding full in-memory buffering, effectively resolving OOM issues under concurrent load.
- Leveraged S3 multipart uploads to support large files with parallelized chunk transfers, improving upload resilience and throughput while reducing the impact of network instability on client operations.
- Integrated a caching layer for S3 metadata to reduce the number of redundant API calls to AWS.
Security & Reliability
- Leveraged AWS IAM roles and policies to ensure Least Privilege access for the .NET service layer.
- Implemented pre-signed POST policies for all client uploads, enforcing strict constraints such as file size limits, content-type validation, and object key scoping directly at the S3 level. All signed requests were short-lived and tightly scoped, minimizing exposure and mitigating replay risks while ensuring that invalid or malicious payloads were rejected before reaching internal systems.
Impact & Results
Reflection
What I Learned
What I'd Do Differently
What I'm Proudest Of
I am proudest of the quantifiable impact this had on the business. It wasn't just a technical cleanup; it was a strategic move that saved the company money and made the platform noticeably faster for our customers. Successfully moving that much legacy data without a single byte being lost or corrupted was a major professional win for me.