AI-Powered Error Normalization: Building a Semantic Translation Layer
Implementing a heuristic fingerprinting engine and Cache-Aside strategy to standardize disparate carrier API responses, reducing LLM costs and providing human-readable clarity for end-users.
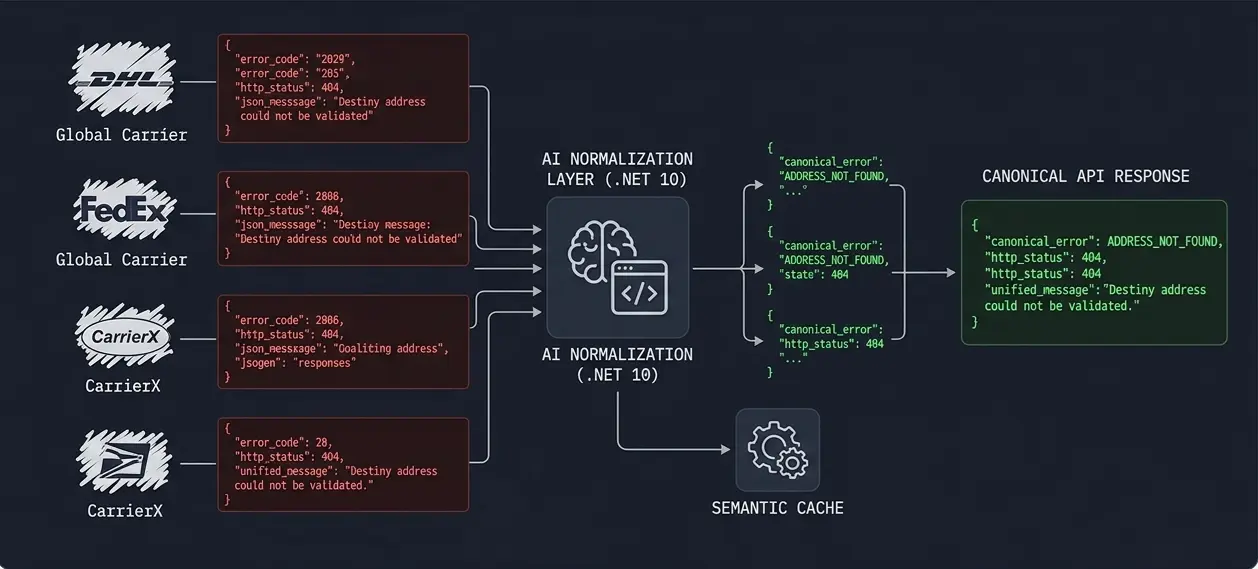
Overview
In a multi-carrier logistics environment interacting with various platforms (WooCommerce, Jumpseller, and proprietary legacy apps), error messages are notoriously inconsistent. They range from cryptic technical stack traces to verbose, unstructured JSON payloads. This lack of standardization made it impossible to provide clear feedback to users or build automated retry logic.
To solve this, I developed a sophisticated Error Identity service that acts as a proxy middleware between raw carrier API responses and the final user interface. The system utilizes a custom Heuristic Noise Filter and Regex-based Normalizer to strip out transient data. By flattening unpredictable JSON structures into a collection of uniform nodes and hashing them, the system identifies recurring error patterns. This enables a Semantic Cache where we only call an OpenAI translation service for entirely new error structures, drastically improving response times and minimizing operational costs.
Goals & Challenges
Goals
- Standardize thousands of disparate carrier error messages into a single, canonical set of human-readable translations.
- Minimize OpenAI API token expenditure by implementing a high-efficiency Cache-Aside strategy.
- Automate the identification of Error Families using structural fingerprinting rather than simple string matching
- Improve developer productivity by filtering out technical noise from production logs.
Key Challenges
- Managing unstructured error payloads that arrive in wildly unpredictable nested JSON schemas across different integrations.
- Preventing 'Token Hemorrhage' where redundant calls for the same error type would inflate AI costs.
- Ensuring that normalization filters (like ID stripping) didn't accidentally remove critical diagnostic information.
Major Problems
- The primary bottleneck was the Noise-to-Signal ratio. Carrier responses frequently included unique request IDs or timestamps in every message, which made traditional string-based caching 100% ineffective until the fingerprinting engine was implemented.
Process Flow
Data Transformation Pipeline
Solutions & My Contributions
Technical Architecture
- JSON Decomposition (NodeLeaf Extraction): Developed a utility to parse and flatten complex JSON trees into a standardized NodeLeaf collection (extracting Path, Type, and Value), allowing for structural analysis regardless of nesting depth.
- Canonical Fingerprinting: Built a deterministic pipeline that alphabetically sorts the surviving nodes and applies a SHA-256 algorithm. This creates a permanent, immutable hash identity for recurring error structures.
- Multi-Level Cache Strategy: Implemented a two-tier architecture using a fast .NET Memory Cache (L1) for instant lookups, backed by a persistent Database Layer (L2) for long-term pattern recognition and L1 hydration.
Performance Optimizations
- Hard Noise Filtering: Created a deterministic filter to immediately drop nodes containing high-entropy data (timestamps, GUIDs, IPs, and PII) before processing.
- Regex Normalization Pass: Designed compiled Regex filters to replace surviving dynamic strings with standardized {PLACEHOLDERS}, ensuring that subtle variations of the same error yield the exact same structural hash.
Analytics & Monitoring
- Efficiency Analysis Tool: Built a diagnostic suite to calculate 'Cache Hit Potential,' proving that the system could eliminate up to 90% of redundant AI translation calls based on historical error logs.
Impact & Results
By fingerprinting structural patterns, the system avoids calling the LLM for any error family it has seen before. 98% of known errors are resolved via the Memory Cache, providing instant feedback to the frontend without waiting for external API calls. Successfully translated technical shipper jargon into actionable customer instructions (e.g., 'Invalid Postal Code' instead of 'Exception at Service.Address.Validator.Line 402').
Reflection
What I Learned
What I'd Do Differently
What I'm Proudest Of
I am proud of the Noise Filter logic. Seeing the system successfully identify that a 50-line stack trace and a 1-line error message were actually the 'same' underlying issue was extremely satisfying. It turned a chaotic log into a clean, manageable dashboard.